前幾天都是介紹單純雜訊輸入,然後生成圖片,這麼做的做法會使GAN生成的結果變得不可控,我們無法依據原本的GAN來生成指定的數字圖片。為了要解決這個問題,2014年底有科學家提出了條件式生成對抗網路 (Conditional Generative Adversarial Networks, CGAN)。CGAN到底動了甚麼手腳,以至於可以生成指定圖片呢,接著就來介紹CGAN吧。
CGAN可以通過額外的訊息輸入至生成器並對生成器增加條件控制,並以此來指導資料生成的過程。它的優點是可以控制GAN生成的圖片,而不是單純的隨機生成圖片。而缺點是需要有足夠的條件數據,並且同樣可能存在模式崩塌或訓練不穩定的問題。
CGAN的目標函數與GAN非常非常像,只是在生成器與鑑別器中的表達方式變成條件機率的寫法而已,也就是加入條件資訊到生成器與判別器,接著與GAN的目標函數算法如出一轍。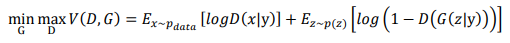
根據原始論文,CGAN也是使用全連接 (Dense)模型來生成mnist手寫資料集。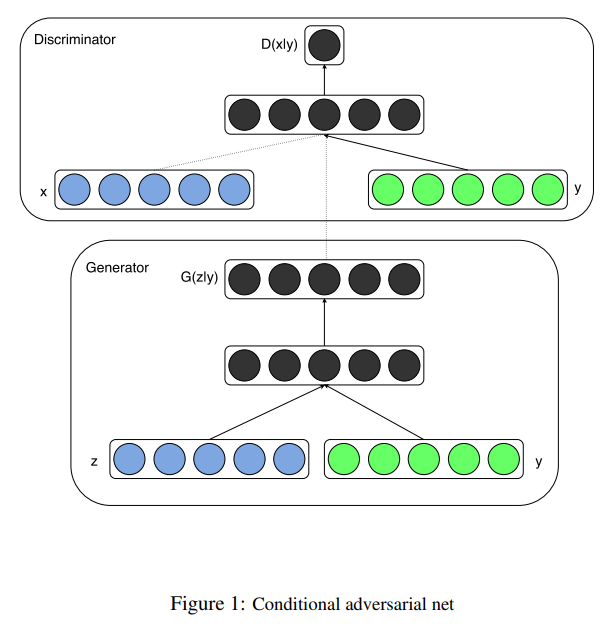
CGAN的對抗模型架構。[圖源]([1411.1784] Conditional Generative Adversarial Nets )
但之後實作會使用DCGAN外加條件輸入,使用CNN為主的模型更能讓生成器學習到圖片的特徵。至於CGAN原始論文會使用全連接模型是因為使用CNN的DCGAN是在2015年被提出的,而CGAN是在2014年11月被提出。
CGAN與GAN的差異是在生成器和判別器中都加入了條件變量,使得生成器可以根據條件變量生成相應的數據,而判別器可以根據條件變量判斷數據的真偽。
不同點就這樣了,非常精簡、簡潔,但條件控制在未來也有許多不同的應用方式,以及廣泛的應用層面,所以CGAN只是開創先例,為一個普通的原始GAN加入條件輸入。在之後的Pix2Pix、擴散模型等等也會與條件輸入有關係,這部分就到時候再來燒腦吧!
今天開始介紹了CGAN,這對於要指定輸出特定條件的一些圖像生成任務來說也是很基礎的觀念,因為CGAN的數學原理與內容真的偏少,大部分都在GAN介紹過了,看起來好像水了一天。明天會來介紹如何實作出CGAN來,希望各位在學會以後根據自己的條件來生成特定的圖片。


 iThome鐵人賽
iThome鐵人賽